Overview
The AWS Sagemaker AI framework uses CodePipeline as the workflow orchestrator. It manages tasks such as building, deploying, testing, preparing data, training models, running inferences, and evaluating results. We define this pipeline using Python CDK in a CloudFormation template, and it operates within the same AWS account.
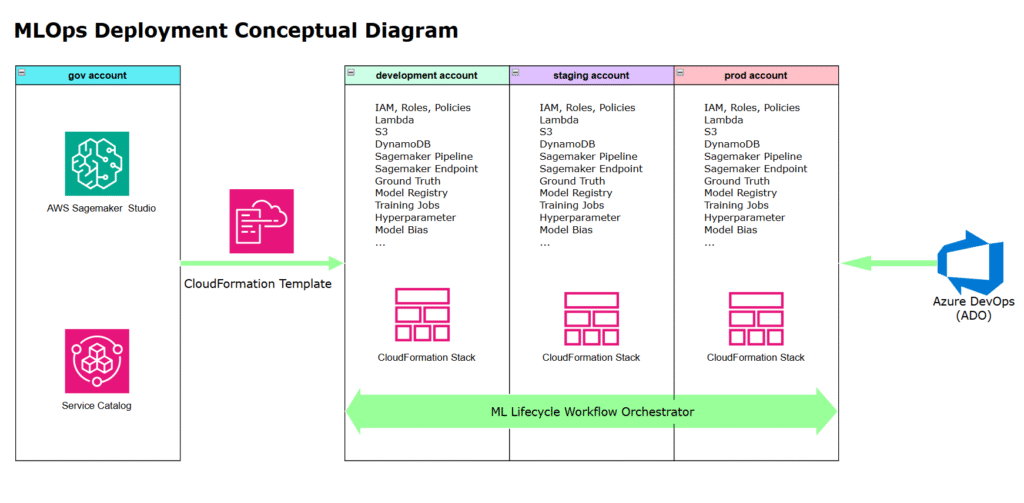
The above diagram illustrates the following sequence:
1. A Data Scientist creates a SageMaker project using an ML-Ops CloudFormation (Cfn) template.
2. The template provisions a set of AWS resources along with a workflow orchestrator that coordinates them across three AWS accounts.
3. The workflow orchestrator reacts to code changes in Azure DevOps (ADO), triggering deployment, ETL processing, model training, and evaluation
4. The orchestrator accesses AWS resources, operates within a VPC and subnet to process data, and complies with IAM policies and the principle of least privilege.
AWS Codepipeline over ADO as the Workflow Orchestrator:
Fundamentally, ML-Ops uses CodePipeline as the execution engine for both DevOps and operational tasks—often overlooked—such as Data Extract, Transform and Load (ETL), model training, and model inference. These tasks require access to AWS services like S3, OpenSearch, DynamoDB, KMS, Secrets Manager, and API Gateway, with each step granted only the permissions necessary to uphold the least privilege principle. Therefore, choosing AWS Codepipeline over ADO as the ML Lifecycle Workflow Orchestrator has the following advantages:
Stronger Security – Native IAM integration enforces the least privilege without cross-cloud credential risks.
Python-Native – Data scientists can define pipelines in AWS CDK using Python — no YAML, no extra tooling.
Better for Long-Running ML Tasks – Avoids ADO’s timeout issues and complex token management by using IAM roles.
Dynamic & Self-Mutating – Easily adapts pipelines at runtime (e.g., per-model branching) without step-level permission overhead.
The key advantages explained below.
Fine-Grained IAM to enforce the Least Principle Privilege
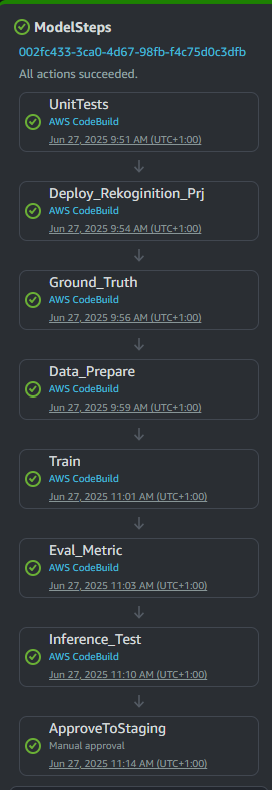
Below is a simple CodePipeline that consists of several steps. Each step defines an independent execution environment and are controlled (or constrained) by multiple parameters. For example:
Deploy_Rekognition step requires security IAM policy allowing Cloudformation template deployment.
Ground_Truth step requires IAM policy with permission to access and retrieve information from a specific S3 bucket, and to save ground truth to AWS Recognition.
Data_Prepare step requires IAM policy with permission to update Rekognition dataset.
Train step requires IAM policy with permission to start Rekognition training job
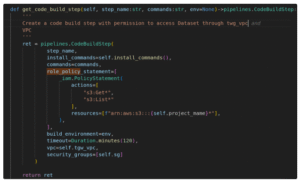
Following is the code snippet to define a step in AWS CodePipeline with specific permission, VPC, and Subnet:
AWS Sagemaker Studio as the preferred interface
AWS SageMaker Studio is chosen as the primary interface for creating ML-Ops CloudFormation stacks. Alternatives like starting from an ADO Pipeline exist, but SageMaker Studio offers the most user-friendly experience. The main users—data scientists— can define pipelines in AWS CDK using Python. The data scientists are already familiar with this environment for model training and running Jupyter notebooks, making adoption seamless.
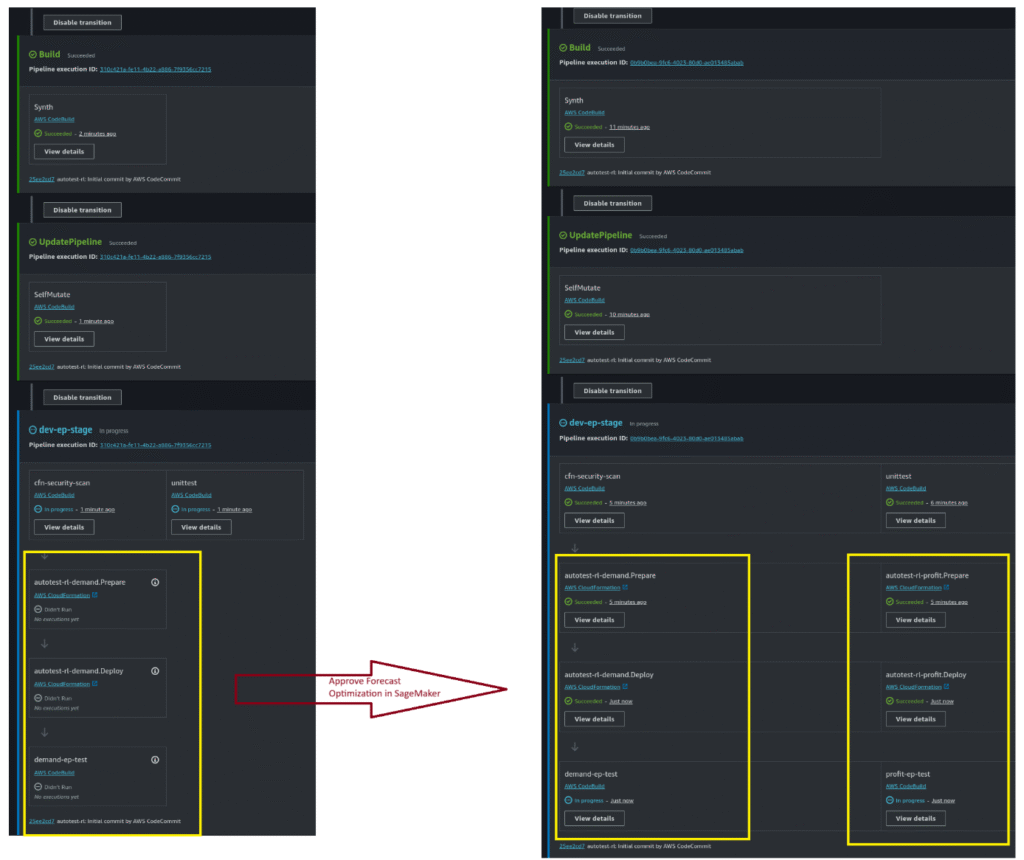
Dynamic and Self-Adjusting Pipeline based on AWS Resources
CodePipeline runs within the same AWS account, allowing it to access resource information and adjust itself dynamically. Following is a sample of such use case:
Initial Execution – Pipeline starts with no inference models.
Approve Demand Optimization Model – Data scientists approve the demand optimization model in SageMaker Studio. Pipeline detects approval, auto-adjusts to a single-branch pipeline, and performs inference (left diagram).
Approve Profit Optimization Model – Data scientists approve the second model. Pipeline detects both approvals and reconfigures into a two-branch pipeline (right diagram).