Overview
Incorporating Generative AI (GenAI) into your anomaly detection process can make workflows more adaptive, context-aware, and capable of reasoning. This project showcases how GenAI can be leveraged to create predictive maintenance workflows using Amazon Bedrock.
Retrieval Augmented Generation (RAG) with knowledge bases
With RAG (Retrieval-Augmented Generation), you can enhance foundation models using company-specific data without having to retrain them constantly. Continuous retraining is costly and time-consuming, and by the time a model is retrained, new data may already make it outdated. RAG solves this by giving your model access to external data at runtime, which is then added to the prompt to improve the relevance and accuracy of its outputs.
This external data can come from various sources, such as document stores or databases. A common approach is to break your documents into smaller chunks, convert them into vector embeddings using an embedding model, and store these embeddings in a vector database, as illustrated in the figure below.
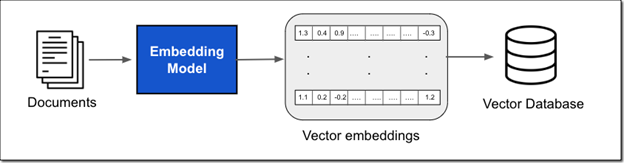
Vector embeddings turn the text in your documents into numeric representations that capture their meaning and context. Each embedding is stored in a vector database, often along with metadata linking back to the original content. The database indexes these vectors, making it fast and easy to retrieve relevant information.
Unlike traditional keyword searches, vector search can find relevant results even without exact word matches. For instance, if you search for ‘What is the cost of product X?’ but your document says ‘The price of product X is…’, keyword search might fail because ‘price’ and ‘cost’ are different words. Vector search, however, understands their semantic similarity and will return the correct result. Similarity is measured using metrics like cosine similarity, Euclidean distance, or dot product.
These vector databases are then used in the prompt workflow to efficiently pull in external information based on a user query, as illustrated in the figure below
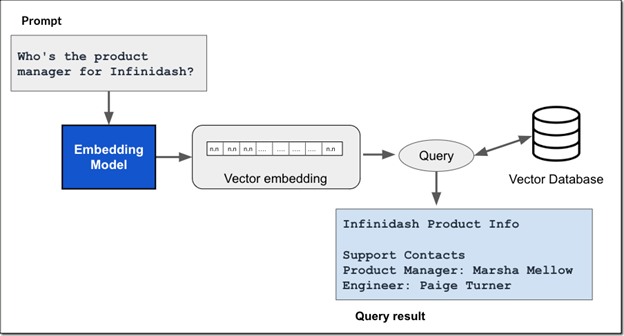
The workflow begins when a user submits a prompt. Using the same embedding model, the prompt is converted into a vector embedding. This embedding is then used to search the vector database for similar embeddings, returning the most relevant text.
The retrieved text is added to the original prompt, creating an augmented prompt that is passed to the foundation model. The model leverages this extra context to generate a more accurate and relevant response, as illustrated in the figure below
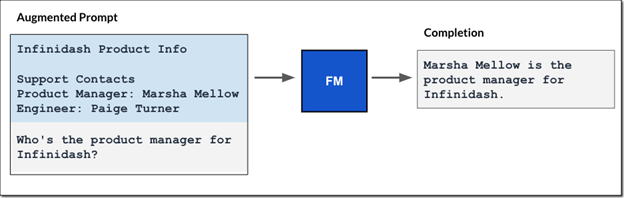
Amazon Bedrock knowledge bases handle data ingestion and provide APIs for retrieving information. You can read more about these concepts in this AWS blog. Now that we understand how knowledge bases fit into the RAG workflow, let’s continue with the project.
Use Case
A company operates several electric motors across its industrial facility, sourced from multiple suppliers. Each motor comes with a manufacturer-provided PDF detailing its specifications. The task is to build the following solution
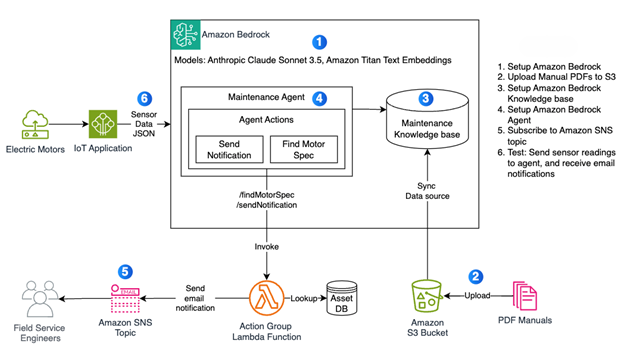
The company operates an IoT data pipeline that aggregates sensor readings from electric motors every five minutes. Your task is to build a Generative AI–powered anomaly detection solution that analyzes this data, compares it against manufacturer specifications, and alerts the appropriate field service team when anomalies are detected.
The sensor data includes only the motor ID, while the motor model and field service group ID are stored in the company’s asset database. The solution must query this database to retrieve the necessary information. Below is a sample of the aggregated sensor data in JSON format, followed by a sample asset database prepared for this problem.


Amazon Bedrock Setup
To tackle this project, we’ll be leaning on some powerful AI tools. Amazon Bedrock gives you access to a variety of foundation models from different providers. For our solution, we’ll focus on two key models:
• Amazon Titan Embeddings Text v2 (amazon.titan-embed-text-v2:0)
• Anthropic Claude 3.5 Sonnet (anthropic.claude-3-5-sonnet-20240620-v1:0)
Next, let’s walk through how to set up access to these models in Amazon Bedrock.
1. Find Amazon Bedrock by searching in the AWS console.
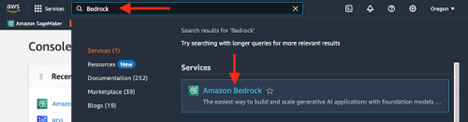
2. Expand the side menu

3. From the side menu, select Model access.

4. Select the “Enable specific model” or “Modify model access button.
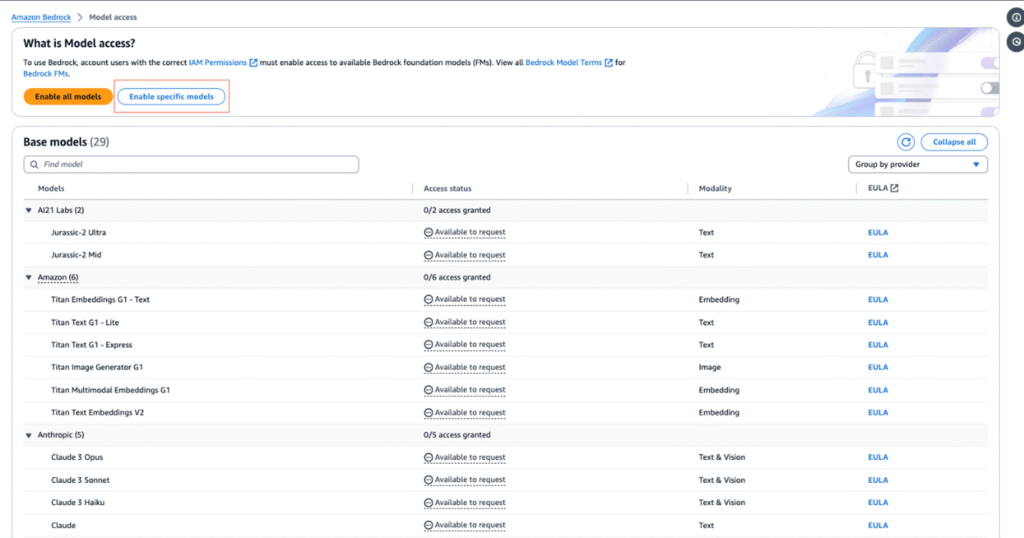
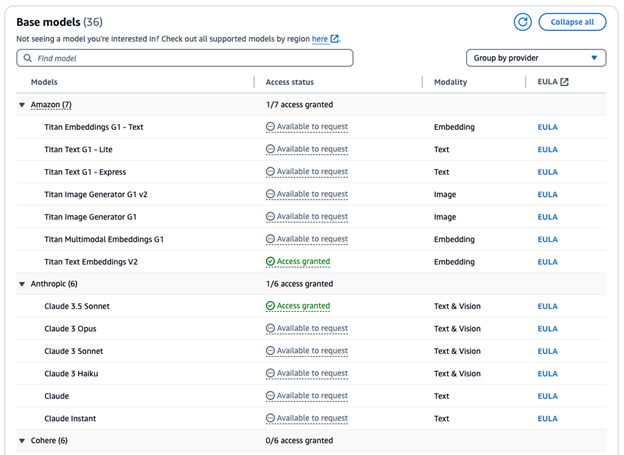
5. Select the checkboxes listed below to activate the models. Review the applicable EULAs about your cloud cost for this service as needed. For this project select the following models:
• Cloud 3.5 Sonnet
• Titan Embedding Text v2
Click “Next” to activate the models in your account.
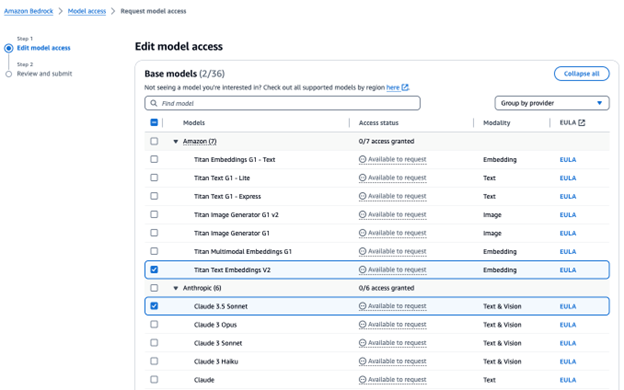
6. Review and submit your models
7. Make sure the models you selected show that access has been granted
Create knowledge base For Predictive Maintenance
Next, we’ll create a knowledge base in Amazon Bedrock that uses OpenSearch Serverless to store vectors. The Amazon Titan Text Embeddings v2 model will turn our documents into vector embeddings for fast, intelligent search.
Upload Knowledge Base Document to S3
First, let’s get the electric motor manuals into S3:
1. In the AWS Console, go to Amazon S3 and open the bucket pm-manuals-bucket.
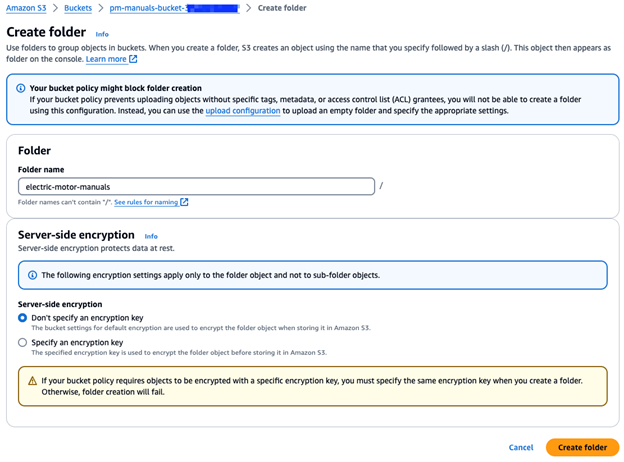
2. Click Create Folder.
3. Name it electric-motor-manuals and leave the rest as default. Hit Create—and you’re ready to upload your PDFs!
4. Open the newly created electric-motor-manuals/ folder and upload your PDF files.
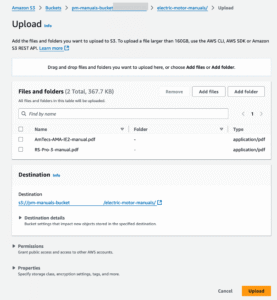
5. Make sure the PDFs have been uploaded successfully before moving on.

Create Knowledge Base
Now let’s build your knowledge base in Amazon Bedrock:
1. In the Amazon Bedrock Console, go to Knowledge Bases from the side menu.
2. Click Create Knowledge Base to launch the builder.
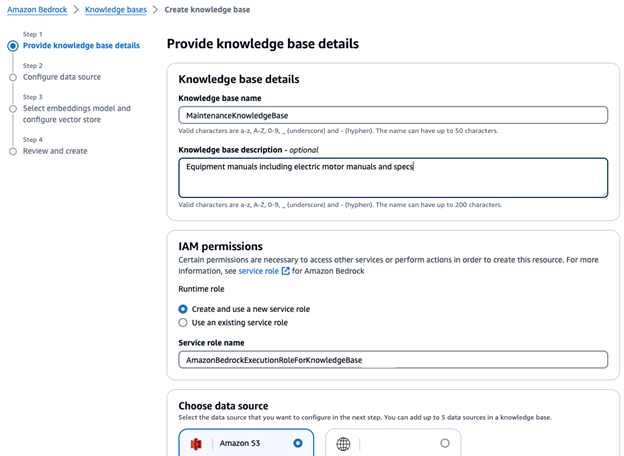
3. Enter the details:
Name: MaintenanceKnowledgeBase
Description: Equipment manuals including electric motor manuals and specs
Data Source: Amazon S3
4. Click Next—and you’re ready for the next step!
5. Once the folder is selected, confirm the S3 URI and click Next to move forward with building your knowledge base.
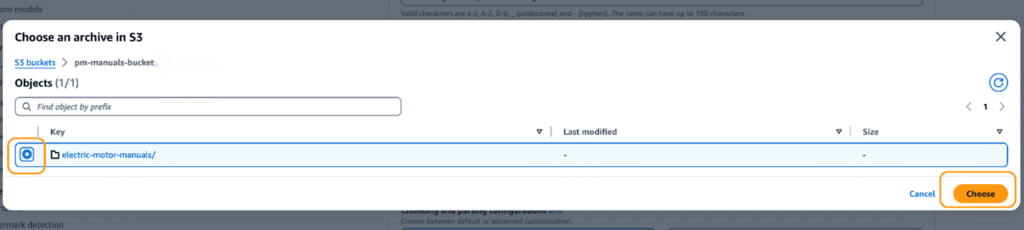
6. Leave other options as default and click next.
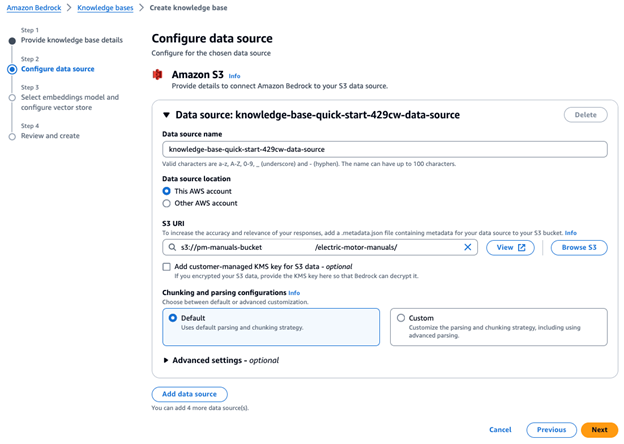
7. On the Select Embeddings Model and Configure Vector Store screen, choose Titan Text Embeddings v2 as the embeddings model. For the vector database, select Quick create new vector store – Recommended. Keep the other settings at their default values and click Next.

8. Review and create the knowledge base. This can take several minutes, keep this tab open until the knowledge base is created.



Sync the Data Source
After creating the knowledge base, you need to sync the data source so the documents are ingested into the vector database and ready for queries. Go to the Data source(s) section, select your S3 data source, and click Sync.

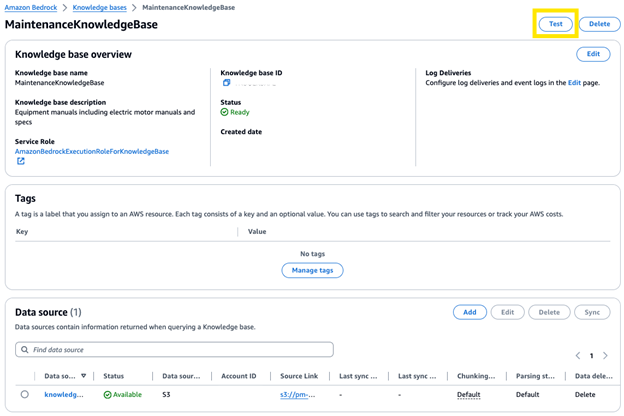
Test the Knowledge Base
After the sync is complete, you can test your knowledge base using the test playground in the Amazon Bedrock console. Click Test to open the test panel.
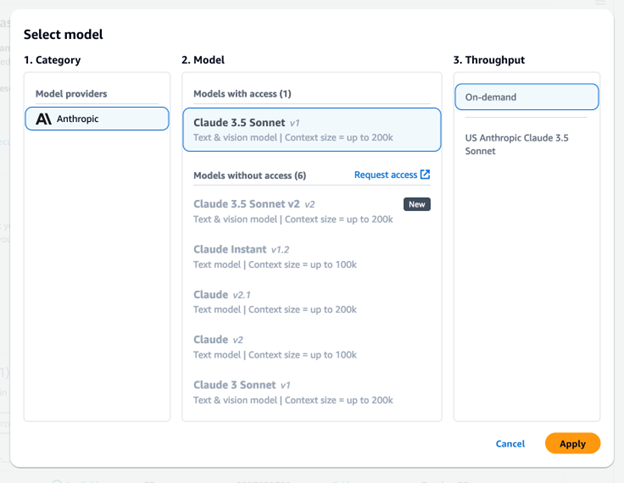
Select Claude 3.5 Sonnet with Throughput On-demand and click Apply.
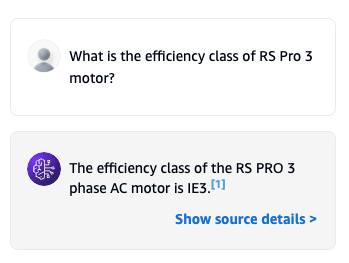
Your test interface should now resemble the image below. Use the message box at the bottom of the panel to interact with the knowledge base.Try asking a few questions about the electric motors you’ve uploaded to see the knowledge base in action. For example, you could ask:
What is the efficiency class of the RS Pro 3 motor?

The test results should look similar to the image below:
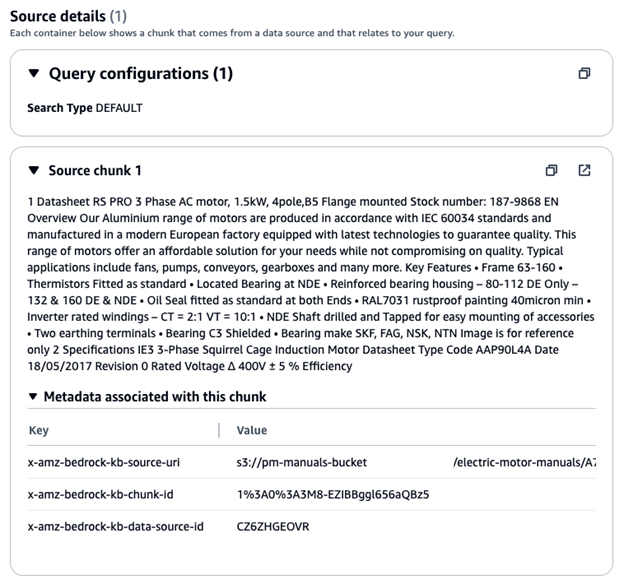
Click on Show Source Details to explore the document chunks the knowledge base retrieved to generate its responses.
You’ve now set up an Amazon Bedrock knowledge base using an S3 data source. With this knowledge base, LLMs can generate accurate, relevant responses to technical questions about electric motors, grounded in your company’s data. Next, let’s move on to building the predictive maintenance agent.
Build the Predictive Maintenance Agent
Now that your knowledge base is ready, we can create a predictive maintenance agent that uses it to support real-time operations:
1. Connect IoT Sensor Data: Aggregate data from your electric motors (vibration, temperature, current, RPM, etc.) using your IoT pipeline.
2. Detect Anomalies: Use Generative AI to analyze sensor data and compare it against the knowledge base specifications to detect deviations.
3. Generate Recommendations: When an anomaly is detected, the agent queries the knowledge base for relevant procedures or specifications and produces actionable recommendations.
4. Notify Field Service Teams: Integrate the agent with your internal workflow tools or CMMS to alert the appropriate personnel.
How It Works
The agent follows a RAG workflow:
1. A user query or sensor alert is converted into a vector embedding.
2. The embedding queries the knowledge base to retrieve relevant information.
3. The retrieved context is combined with the original query and sent to the LLM.
4. The LLM generates a response or recommendation grounded in your documents and operational data.
With this setup, your LLM stays up-to-date with the latest company data without retraining.