Overview
Retrieval-Augmented Generation (RAG) is quickly becoming a standard design pattern for grounding Large Language Models (LLMs) with external knowledge. Instead of relying solely on the training data of the model (which may be outdated or incomplete), RAG retrieves relevant facts from a knowledge base and passes them into the prompt. This ensures responses are more accurate, transparent, and trustworthy.
In this post, I’ll walk through a production-ready RAG template built on AWS SageMaker, covering its architecture, components, and how you can get started.
What’s in the RAG template?
This is an end-to-end RAG implementation running fully on AWS infrastructure. The template includes the following components:
• Data Vectorization – embedding documents into vector space with Amazon Bedrock Titan Embeddings.
• Vector Store – fast semantic search powered by ChromaDB (in-memory, S3-backed).
• Search & Relevance – hybrid retrieval with semantic search, keyword search, and reranking.
• LLM-based Content Generation – powered by Bedrock-managed foundation models.
• Prompting – configurable system prompts stored in Lambda environment variables.
• Streamlit UI – lightweight front end for testing and demos.
The template provides APIs (Lambda + API Gateway) to support four RAG use-cases:
• Content Generation
• Semantic Search
• RAG Q&A
• RAG Conversation (chatbot-style with memory)
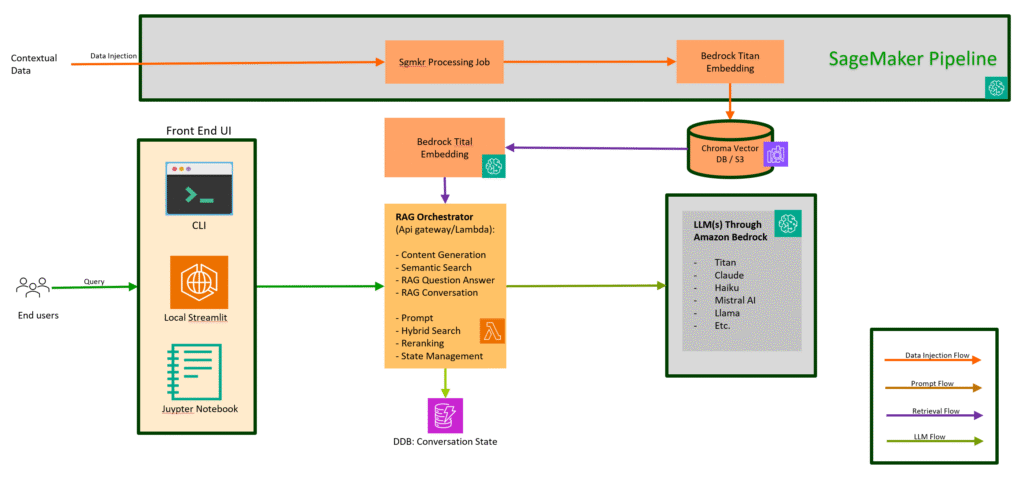
MVP Architecture
The diagram below illustrates the Minimum Viable Product of RAG pipeline:
Embeddings
At the core of Retrieval-Augmented Generation (RAG) lies the ability to convert raw text into embeddings — numerical representations that capture the meaning of the text.
In this template, we use Amazon Bedrock’s Titan Embedding model to generate these vector representations. Each document (for example, financial reports or knowledge base articles) is split into chunks, embedded into vectors, and then stored for efficient retrieval.
Vectorization
Data Source: by default, the system uses a pre-defined s3 bucket as the data source. The folder contains quarterly profit reports from Apple in PDF format. The system defines a SageMaker processing job (as shown below) to convert the PDFs into vector store.
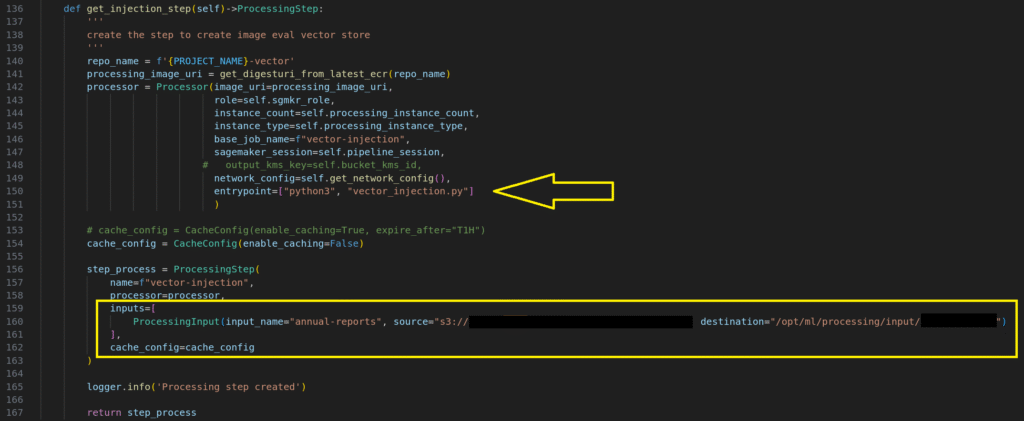
Pipeline Processing Step
During processing, the pipeline:
1. Reads PDF files from the designated folder.
2. Splits the documents into chunks.
3. Injects the chunks into the vector store.
4. Saves the vector store to Amazon S3 in Chroma DB format using the following naming convention:
s3://project_name-region-account/chroma-vector-store
📄 Source Documents (PDFs in S3)
│
▼
🧩 Document Chunking
│
▼
🔢 Bedrock Titan Embedding Model
│
▼
📦 Vector Store (ChromaDB in-memory, persisted to S3)
│
▼
⚡ Lambda Loads Vector Store → Retrieval + RAG Queries
Vector Store:
The system uses ChromaDB as the default in-memory vector database. During runtime, AWS Lambda functions load the vector store from S3 directly into memory
Lambda as Orchestrator
We use AWS Lambda as an orchestrator to invoke LLM and embedding models. Clients can specify the model provider (e.g., Amazon Bedrock) and model name via Lambda environment variables. Lambda leverages IAM credentials to call these models, so no API keys are required.
Retrieval Algorithms
The RAG Q&A use-case in this template supports the following retrieval approaches:
- Vector-based Semantic Search
- Retrieves documents based on semantic similarity in embedding space.
- Hybrid Search
- Combines keyword search and vector search using Reciprocal Rank Fusion (RRF).
- Reference: LangChain Ensemble Retrievers
- Metadata Filtering with Self-Query
- Allows filtering results based on document metadata using dynamic queries.
- Reference: LangChain Self-Query Retriever
- Semantic Reranking
- Reorders retrieved documents based on semantic relevance.
- FLARE (Forward-Looking Active Retrieval)
- Implements active retrieval to anticipate useful information in the query context.
- LangChain Implementation:
langchain.chains.flare.base.FlareChain
Bedrock-based LLM
Amazon Bedrock provides a simple, scalable way to build generative AI applications using foundation models (FMs). It is a fully managed service that offers high-performing models from leading AI companies—including AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon—via a single API, along with a broad set of capabilities build generative AI applications with security, privacy, and responsible AI.
CodePipeline
Once provisioned, the system creates {project-name}-rag-ragapp codepipeline. this pipeline deploys lambdas, create vector store, and inject documents into the vector store.
Lambdas
We use AWS Lambda as an orchestrator to invoke LLM and embedding models. The system provides four Lambda functions:
- Semantic Search
- Performs semantic search in the vector database.
- Content Generation
- Uses the LLM to generate content based on a given prompt.
- RAG Question & Answer
- Executes semantic search based on the user’s question.
- Sends retrieved results to the LLM to generate an answer.
- Represents the typical RAG workflow.
- RAG Conversation
- Similar to RAG Q&A but with conversation memory.
- Supports multi-turn dialogue for chatbot scenarios.
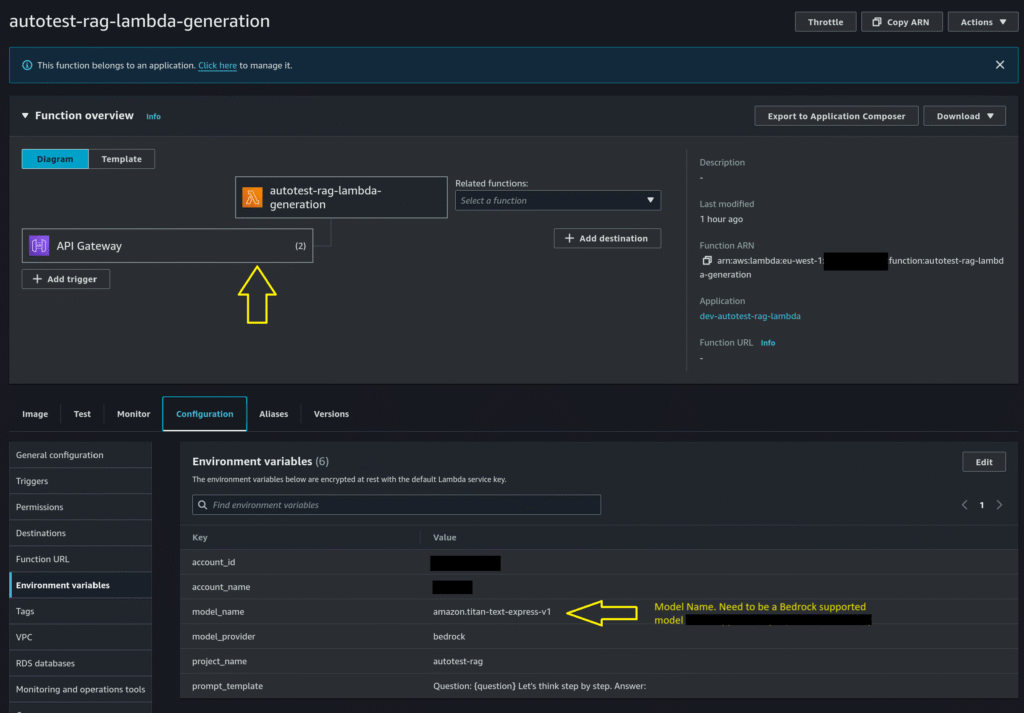
Prompt Management
System prompts are stored as part of the Lambda environment variables. User can change the system prompt as shown here in the Lambdas section below.
Lambda Environment Variables
We use environment variables to configure the lambda as shown in the picture below.
Quick Start Guide
Follow the steps to try out the application:
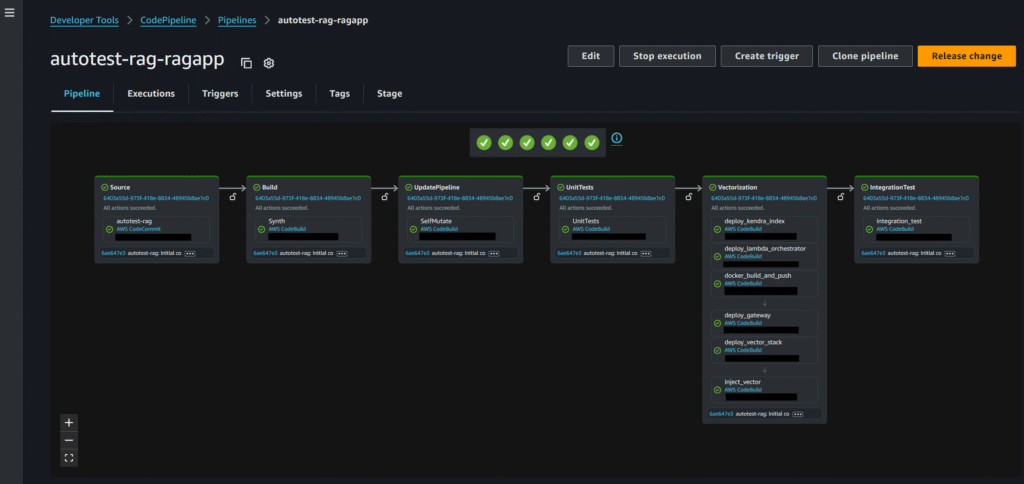
- Kick off by launching a new SageMaker project in SageMaker Studio with the RAG template. Give your project a name—say, autotest —to set things up.
- Once the project is created, a CodePipeline named autotest-rag-ragapp will appear in your AWS development account. This pipeline automatically provisions the required Lambda functions and loads the initial set of documents—in this case, Apple quarterly profit report—into the vector database. The end-to-end pipeline run takes about 30 minutes, and you should confirm that the integration tests pass successfully once it completes
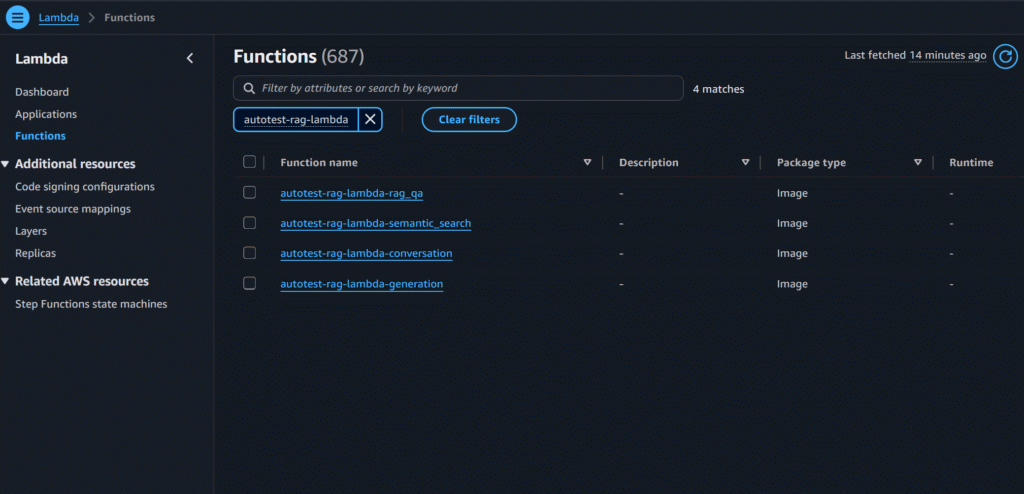
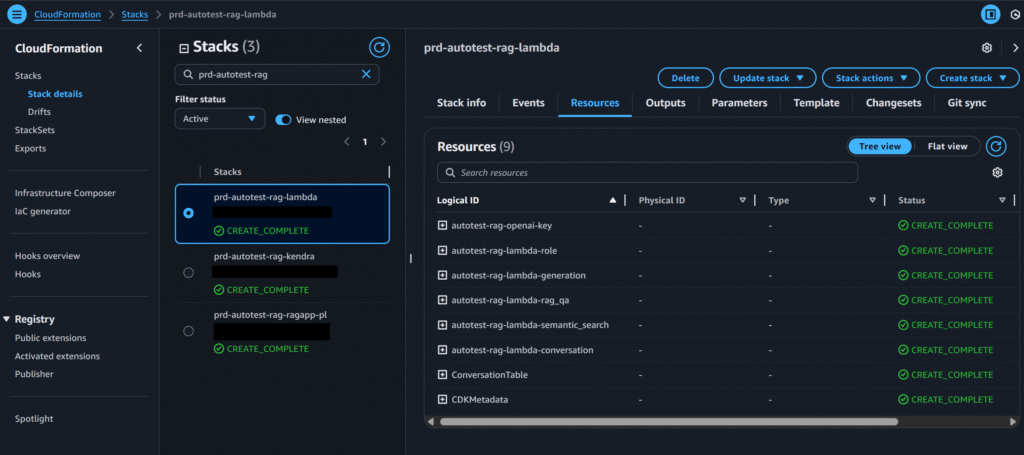
3. Next, run the CLI demo.
a. Start by opening the configuration file and updating the profile and project_name fields to match yours.
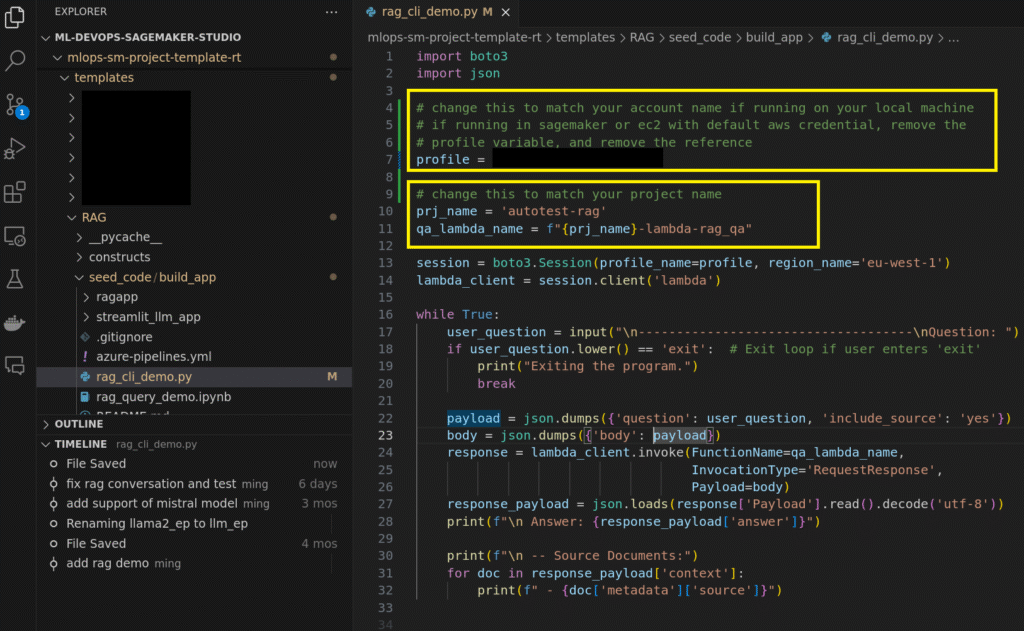
b. Run the demo using the command: python rag_cli_demo.py
Once it’s running, you can start asking questions. The system will respond with answers grounded in the Apple quarterly profit reports, as shown in the example output below
