What is Machine Learning?
In essence, it is a type of Artificial Intelligence that extract patterns out of raw data by using an algorithm or method. The key focus of Machine Learning is to allow computer system to learn from experience without human intervention or being explicitly programmed.
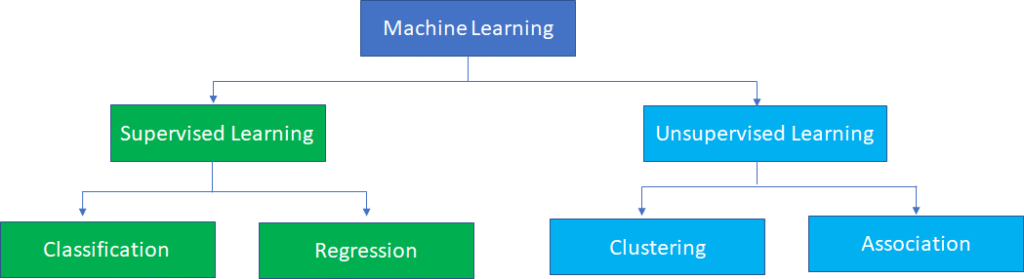
Two categories of Machine Learning are: Supervised Learning and Unsupervised Learning.
1. Supervised Learning
It is one paradigm of Machine Learning where the algorithm is used to best estimate the mapping function ( f ) from an input set of data (X) in order to predict the output (Y) for that set of data.
Y = f (X)
The output (Y) are labelled and the Supervised Learning algorithm are trained using labelled data.
Supervised Learning can be grouped into:
1.1. Classification
1.2. Regression
By understanding whether the Machine Learning task is a classification or regression is key for selecting the right Supervised Learning algorithm to use.
1.1. Classification
Classification involves assigning the target feature a Label. The Classification algorithm is then used to estimate the mapping function (f) from an input set of data (X) in order to obtain discrete output (Y).
The target examples of binomial classification are: 1 or 0, Yes or No.
The target examples of multinomial classification are: Positive or Negative or Neutral.
Real life examples:
- Email Spam Classification: Given a dataset of emails, the aim is to predict which incoming email is labelled as Spam or No Spam
- Weather Prediction: Given a dataset of weather, the aim is to predict the rain will happen tomorrow at 9am is labelled as Yes or No
- Credit Approval Classification: Given a dataset of thousands of credit applications which contain different attributes such as Annual Salary, Debt history, Age, credit rating etc. The aim is to predict which credit application falls under Approved or Not Approved or Need Review
- Sentiment Analysis Classification: Given a dataset of users tweets on one issue on Twitters of several cities. The aim is to predict which city has Positive or Negative or Neutral sentiment.
1.2. Regression
Regression involves assigning the target feature a Label. The Regression algorithm is then used to estimate the mapping function (f) from an input set of data (X) in order to obtain continuous numeric value output (Y).
Real life examples:
- Stock Market: Given a dataset of a share price of previous time, the aim is to predict the price of the share tomorrow in the form of price range between lowest price and highest price.
- Weather Prediction: Given a dataset of rainfall intensity of previous time, the aim is to predict the amount of rain that will occur tomorrow.
- House Price: Given a dataset of housing price of previous time, the aim is to predict the price range of the house.
- Press publishing: Given a dataset of number of pageviews of various article topics, the aim is to predict the range of number of pageviews of the new article.
2. Unsupervised Learning
It is another paradigm of Machine Learning which looks at recognizing a pattern from the given dataset.
The output are not labelled and the Unsupervised Learning algorithm develops a learning through observation and finds all kind of patterns in data.
The Unsupervised Learning can be grouped into:
2.1. Clustering
2.2. Association
By understanding whether the Machine Learning task is a Clustering or Association is key for selecting the right Unsupervised Learning algorithm to use.
2.1. Clustering
Clustering is the Unsupervised Learning that involves the detection of potentially useful clusters in the data. The Clustering algorithm is then used to discover the inherent group as cluster in the data.
Real life examples:
- Customer Grouping: Given a dataset of customer purchase records, the aim is to group the customers by purchasing behavior.
2.2. Association
Association is the Unsupervised Learning that involves the detection of association rule in the data. The Association rule algorithm is then used to discover the rule that describes large portions of data.
Real life examples:
- Product Association: Given a dataset of customer purchase records, the aim is to associate customers such that people who buy product A tends to buy product B